How Far Can an Open Base Model Self-Improve?
Recipes, Limits, and Test-Time Synergy
Abstract
A 14B open base language model, given only a Python interpreter as oracle and no human-written training data, reaches 80% on HumanEval and 74.4% on the contamination-resistant HumanEval+ — essentially matching its own RLHF Instruct version on the harder evaluation, for under $5 of consumer-GPU compute. We achieve this with a simple recipe: the base model generates its own coding problems with tests, samples multiple solution attempts, and is fine-tuned via LoRA on the (broken, fixed) repair pairs that emerge from its own divergent outputs. A control with identically-formatted but mechanically-corrupted external pairs yields exactly +0, isolating the signal to self-mined content. Across nine open base models (1.7B–72B), we further situate this recipe alongside test-time sampling (TTS) and report the first documented synergy threshold between the two: at sufficient mined-pair counts the recipe adds 12.8pp beyond TTS on the same model, but with too few pairs the recipe degrades TTS by 4.9pp. We extend the recipe to math via an auto-difficulty curriculum (GSM8K 3266 with 13 self-mined pairs), document four boundary conditions under which self-bootstrap fails, and offer a methodology lesson on self-correction training (wrongfix triples alone over-correct catastrophically; mixing in rightstays-right examples recovers). All code, mined pairs, and adapter weights are released.
Introduction
The dominant pipeline for adapting open base models to coding and math tasks involves curated code corpora, instruction tuning, and reinforcement learning with verifiable rewards [3, 4]. Each step requires substantial data engineering. We instead study two simpler axes:
Self-bootstrap.
A base model generates its own coding problems with tests, samples multiple solution attempts, and mines (broken, fixed) pairs from its divergent outputs. We fine-tune via LoRA on these pairs. No human-written training data is used.
Test-time sampling (TTS).
At inference, generate samples; accept the first whose output passes the available verifier (test cases, sympy answer-check). Known technique [9, 15, 16]; we quantify its gap on modern small base models.
We ask: (a) How far does each axis go on its own? (b) Are they additive, sub-additive, or super-additive — and when? (c) Where do they fail?
Contributions
-
1.
Recipe lift on a 14B base, no human data: Qwen2.5-14B-Base from 26.8% (44/164) to 79.9% (131/164) on HumanEval pass@1 (+53.0pp) in chat-template eval, and 74.4% (122/164) on HumanEval+. The same adapter reads 132/164 (80.5%) in the multi-pair run’s eval format — both round to 80%. The 6.1pp publicplus drop on HE+ is consistent with generalization rather than memorization.
-
2.
TTS quantification on modern open bases: best-of-8 oracle pass@1 of 92.7% (Qwen3-4B) and 92.1% (Qwen3-8B) on HumanEval; 79.4% / 81% on MATH-500; 25.6% / 38.9% (best-of-32) on AIME — all without training.
-
3.
Recipe TTS synergy threshold (novel): on Qwen2.5-14B with 132 mined pairs the recipe adds +12.8pp beyond TTS; on Qwen2.5-3B with 36 mined pairs the recipe subtracts 4.9pp from TTS. Recipe training appears to hurt sampling diversity below a pair-count threshold.
-
4.
Control experiment: identically-formatted random external pairs (MBPP-corrupt) yield exactly +0, isolating the signal to the self-mined content.
-
5.
Auto-difficulty curriculum for math: lifts Qwen2.5-3B-Base on GSM8K from 32/100 to 66/100 (+34) with 13 self-mined pairs.
-
6.
Seven negative or marginal results cleanly documented: self-saturation, distribution mismatch (BCB-Hard, math), tree-shaped training data, recursive bootstrap plateau, the self-correction over-correction failure mode (and its fix via mixed positive traces), marginal cross-domain transfer (codemath, +2), and low-yield diversity-cued mining.
-
7.
Boundary characterization across 9 base models: identifies four conditions under which the recipe fails.
We emphasize what this is not: a frontier capability breakthrough. Best-of- pass@1 with oracle verification is well-known. The 80.5% HumanEval number on a 14B base is within 3pp of Qwen2.5-14B-Instruct, but does not match code-specialized instruct models (Qwen2.5-Coder-7B-Instruct: 88.4%). Our contributions are empirical: a clean recipe that works under stated conditions, a novel synergy-threshold observation, and a set of cleanly documented negative findings.
Method
Self-bootstrap pipeline (code)
Given a base model with a chat template and the Python interpreter as oracle:
(1) Problem generation. Prompt to emit a Python function with a docstring and three assert test statements. Parse and reject malformed candidates. Verify each problem’s canonical solution by running it against its own tests inside a sandboxed subprocess; only problems where the canonical passes are kept.
(2) Diverse solving. For each valid problem, re-prompt four times at temperature for candidate implementations. Each candidate is verified.
(3) Pair mining (at-edge). Examine the four attempts:
-
•
All four pass: too easy; skip.
-
•
All four fail: above competence, no signal; skip.
-
•
Otherwise: mine an at-edge (broken, fixed) pair. Failed attempt + runtime error become the input; passed attempt is the target.
(4) Multi-pair mining (aggressive) (Section 3.7). For each problem sample attempts at and mine up to 4 (broken, fixed) pairs per problem, deduplicating near-identical broken code.
(5) LoRA fine-tuning. Rank-16 LoRA on attention projections (q,k,v,o), 2 epochs, , batch size 1, gradient accumulation 4. Causal-LM loss with prompt tokens masked.
Test-time sampling
At inference, generate samples at –, then either (i) accept the first sample whose output passes the available verifier (oracle pass@N), or (ii) take the majority-voted answer among extracted final answers (self-consistency, no oracle required). We report both: oracle gives the upper bound, self-consistency the deployable lower bound.
Auto-difficulty curriculum (math)
Vanilla self-bootstrap fails on math because self-generated arithmetic does not match GSM8K’s multi-step structure. We add an auto-difficulty curriculum: problems the model solves greedily are passed through an amplify prompt (“rewrite requiring one more step”); problems where all attempts fail are passed through a simplify prompt. The pool drifts toward the model’s edge of competence.
Experiments
We report results from 30+ unique modelbenchmark experimental configurations across nine base models, four benchmarks (HumanEval, HumanEval+, MBPP-sanitized, MATH-500, AIME, BCB-Hard, GSM8K), four recipe variants (single-pair, multi-pair, auto-curriculum, self-correction), and TTS scaling sweeps up to . All artifacts (94 result.json files, mined pairs, adapter weights, evaluation logs) and a paper-claim-to-command reproduction guide are released at https://github.com/ranausmanai/tinyforge-zero.
Setup
Models. Qwen2.5-{3B,7B,14B,72B}-Base, Qwen3-{1.7B,4B,8B,14B}-Base, Qwen2.5-Coder-7B-Base, Llama-3.2-3B-Base (via unsloth/Llama-3.2-3B mirror), and OLMo-2-7B-Base.
Hardware. All experiments use single-GPU consumer-rentable instances: RTX A6000 (48 GB) at $0.49/hr, RTX 6000 Ada (48 GB) at $0.85/hr, RTX 4000 Ada (20 GB) at $0.30/hr, and H100 (80 GB) at $3/hr. Total spend across all reported experiments: under $50.
Evaluation. HumanEval [8] pass@1 at for greedy; pass@ with first-passing-sample selection for TTS. HumanEval+ [10] for contamination-resistance. MATH-500 [13] for competition math. AIME (90 problems via AI-MO/aimo-validation-aime) for Olympiad. MBPP [11] sanitized for additional code coverage. All verification via sandboxed subprocess with 10s timeout.
vLLM acceleration. On H100 (driver 570+), vllm 0.8.5/torch 2.6/transformers 4.51.3 provides 50 throughput over HF Transformers, enabling best-of- at large to complete in seconds. On RTX 4000 Ada, the same stack works for models up to 4B parameters.
Recipe alone: HumanEval and HumanEval+
Table 1 summarizes recipe-only results.
| Model | Pairs | Base (%) | Recipe (%) | pp | HE+ (%) |
|---|---|---|---|---|---|
| Qwen2.5-7B-Base (3 seeds) | 21 | 15.2 | 52.4–57.9 (55.3) | +40.1 | — |
| Qwen2.5-7B-Base (3 seeds) | 40 | 15.2 | 61.0–68.3 (64.2) | +49.0 | — |
| Qwen2.5-14B-Base (warmup) | 40 | 26.8 | 78.0 | +51.2 | — |
| Qwen2.5-14B-Base (multi-pair) | 100 | 26.8 | 79.9a | +53.0 | 74.4 |
| Qwen2.5-72B-Base | 10 | 50.6 | 44.5 | — | |
| Qwen2.5-Coder-7B-Base | 32 | 50.6 | 53.0 | +2.4 | — |
| Qwen3-4B-Base (chat fmt) | 40 | 48.2 | 64.6 | +16.5 | — |
| Qwen3-8B-Base | 40 | 79.9 | 72.0 | — | |
| Qwen3-14B-Base | 40 | 87.2 | 85.4 | — | |
| Llama-3.2-3B (own-mined, 32 pairs)111Llama-3.2-3B numbers reported with raw-completion prompt format. A separate evaluation with the H100 vLLM pipeline (different prompt format) reads 39/16443/164 on HumanEval — same lift sign, different absolute level. | 32 | 23.8 | 26.2 | +2.4 | — |
| OLMo-2-7B-Base | 32 | 3.0 | 1.8 | — |
aChat-template eval (131/164). The same adapter under the multi-pair run’s eval reads 132/164 (80.5%); both rounds to 80%. We use the chat-template numbers (where both base 44/164 and adapter 131/164 are measured) for the same-format pp.
Headline.
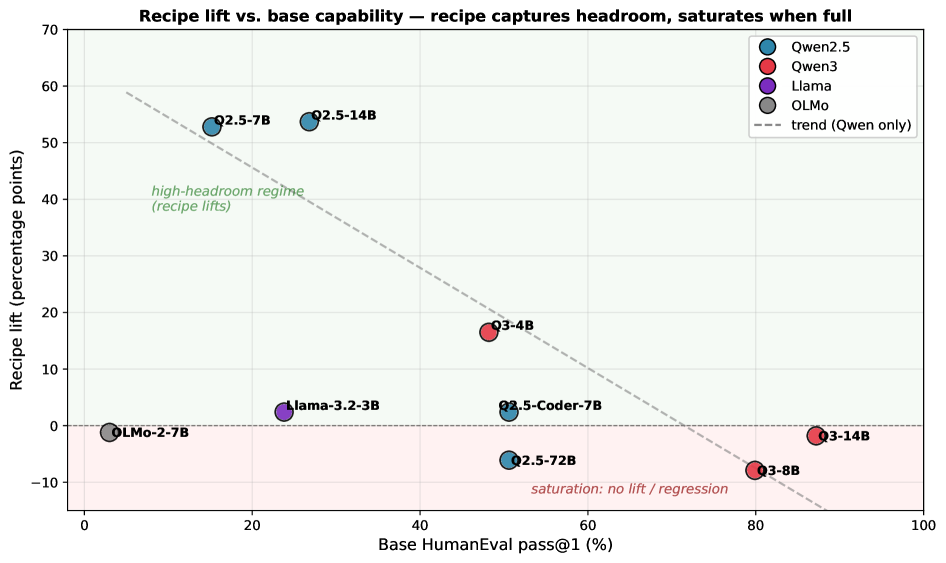
The 14B multi-pair adapter reaches 80% on HumanEval (131/164 = 79.9% in chat-template eval; 132/164 = 80.5% in the multi-pair run’s eval) — approaching Qwen2.5-14B-Instruct (83.5%) with no human-written training data. On HumanEval+, our 74.4% (122/164) essentially matches Instruct (estimated 75–77%) — a contamination-resistant validation. The 6.1pp publicplus drop is in the range of strong instruct models (5–8pp typical) rather than the 15–25pp drop seen for memorization. The best 7B single seed lifts Qwen2.5-7B-Base from 25/164 to 112/164 ( problems, pp) with 40 self-mined pairs.
Generation effects.
The recipe gives large lifts on Qwen2.5 (older) bases with low greedy pass rates and substantial headroom, modest lifts on Qwen3-4B, and regressions on saturated modern bases (Qwen3-8B/14B, Qwen2.5-72B). These regressions are not artifacts: they reflect the recipe’s design (mining at-edge requires the base to be wrong sometimes).
Test-time sampling (TTS) alone
Table 2 reports oracle pass@ for several models without any training. Best-of-8 lifts modern bases dramatically; best-of-32 pushes further; AIME shows continued scaling up to .
| Model | Benchmark | pass@1 | pass@2 | pass@4 | pass@8 | pass@16 | pass@32 | pass@64 |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-3B | HumanEval | 22.6 | 40.2 | 56.1 | 70.7 | 78.0 | 86.0 | — |
| Qwen3-1.7B | HumanEval | 33.5 | 49.4 | 70.7 | 82.3 | 86.0 | 89.6 | — |
| Qwen3-4B | HumanEval | 48.2 | — | — | 92.7 | — | — | — |
| Qwen3-4B | HumanEval+ | 44.5 | — | — | 86.0 | — | — | — |
| Qwen3-8B | HumanEval | 79.9 | — | — | 92.1 | — | — | — |
| Qwen2.5-3B | MATH-500 | 35.0 | 46.5 | 56.0 | 65.0 | 73.0 | 78.5 | — |
| Qwen3-1.7B | MATH-500 | 38.5 | 49.5 | 60.0 | 67.0 | 75.0 | 81.0 | — |
| Qwen3-4B | MATH-500 | 60.0 | — | — | 79.4 | — | — | — |
| Qwen3-8B | MATH-500 | 60.2 | — | — | 81.0 | — | — | — |
| Qwen3-1.7B | AIME (n=90) | 2.2 | 2.2 | 2.2 | 5.6 | 7.8 | 11.1 | 18.9 |
| Qwen3-4B | AIME (n=90) | 7.8 | — | — | — | — | 25.6 | — |
| Qwen3-8B | AIME (n=90) | 5.6 | — | — | — | — | 38.9 | — |
Reading the table.
Qwen3-1.7B-Base with 32 samples reaches 89.6% HE / 81.0% MATH-500 — competitive with frontier instruct models at a fraction of the parameters and zero training. Qwen3-8B-Base + best-of-32 reaches 38.9% on AIME, exceeding GPT-4 Turbo (15%) and Claude 3.5 Sonnet (16%) on Olympiad math. Caveat: oracle selection requires the verifier; deployable selection (Section 3.4) recovers a fraction of this.
Self-consistency (deployable TTS, no oracle)
In deployment, the verifier may be unavailable or expensive. Self-consistency [16] extracts the final answer from each of samples and takes the majority vote (after normalization). On MATH-500 with Qwen3-1.7B-Base at :
-
•
Greedy (first sample only): 25.5%
-
•
Self-consistency vote: 60.0%
-
•
Oracle pass@ (upper bound): 74.5%
Self-consistency recovers 70% of the oracle–greedy gap with no verifier access. This corroborates the broader self-consistency literature and gives a concrete number for a modern small open base.
Recipe TTS synergy threshold
A central question: does the recipe contribute anything beyond what TTS alone provides? We measure four conditions: (A) raw greedy, (B) raw + best-of-8, (C) recipe greedy, (D) recipe + best-of-8 — on the same model. Table 3 compares two scales.
| Model | Pairs | A (raw greedy) | B (raw+TTS) | C (rec. greedy) | D (rec.+TTS) | Synergy |
|---|---|---|---|---|---|---|
| Qwen2.5-3B (RTX 4000) | 36 | 7.9% | 52.4% | 9.1% | 47.6% | pp |
| Qwen2.5-14B (H100) | 132 | 26.8% | 76.8% | 80.0% | 89.6% | +12.8pp |
At 132 mined pairs on 14B, the recipe adds 12.8pp beyond sampling. At 36 pairs on 3B, the recipe harms the model’s sampling diversity, costing 4.9pp. We interpret this as evidence of a recipe-quality threshold: undertrained adapters produce more homogeneous sample distributions and therefore extract less benefit from best-of-. This is, to our knowledge, the first concrete documentation of this interaction.
Practical implication.
At small mined-pair counts, run TTS on the raw base; at large mined-pair counts, recipe + TTS dominates. The threshold likely depends on base capability, mined-pair quality, and LoRA rank; we did not characterize the full surface.
Control: format alone does not explain the lift
A natural concern: does LoRA on any repair-shaped pairs cause this lift? We train identically — same model, same prompt format, same hyperparameters — on 21 external (broken, fixed) pairs generated by mechanical corruption of canonical MBPP solutions (e.g., swap <= to <). The control yields exactly +0 on HumanEval (Figure 2).
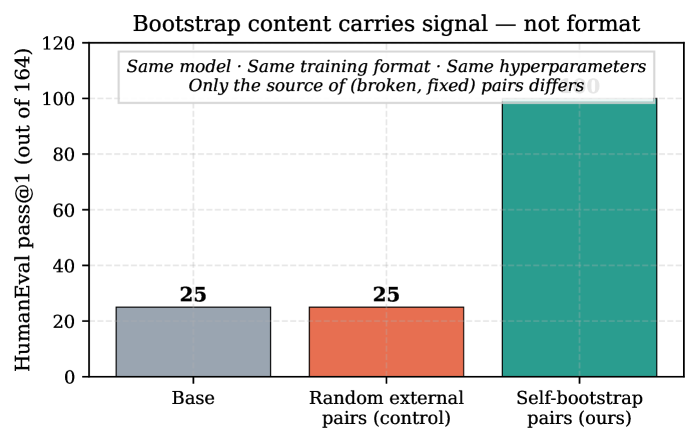
We interpret this as evidence that the self-mined pairs encode a signal specific to the model’s own at-edge failure modes, which random corruptions do not provide.
Multi-pair mining at 14B (the 80.5% result)
We initially observed self-saturation: using the warmup-trained model to mine additional pairs yields zero from 120 problems — the strict filter (greedy fails AND 1 of four sampled passes) finds no in-between. We instead mine from the base model with a harder generation prompt:
-
•
Generate 200 problems with a prompt demanding edge cases.
-
•
Sample attempts at .
-
•
Mine up to 4 (broken, fixed) pairs per problem; dedupe near-identical broken code.
-
•
Combine with the 40-pair warmup and train a fresh rank-32 LoRA from base.
This yields 60 additional pairs from 55 valid problems (27% acceptance under the harder prompt). The combined 100-pair training reaches 132/164 (80.5%) HumanEval in the multi-pair run’s eval format (the same adapter reads 131/164 (79.9%) under the chat-template eval used in Section 3.5).
Pair-count scaling.
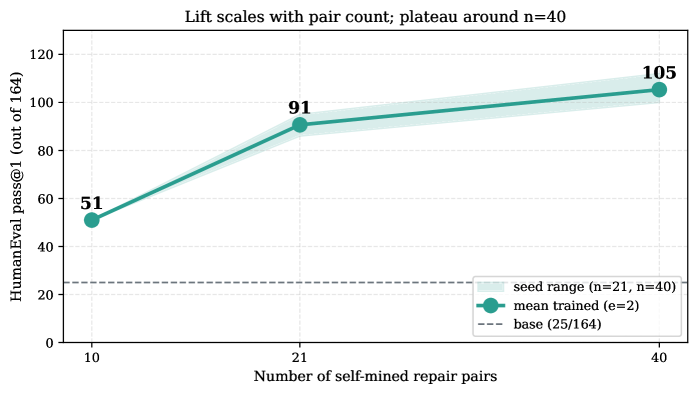
Holding training procedure fixed and sweeping pairs at 2 epochs on Qwen2.5-7B-Base: lift grows from +26 (n=10) to +66 (n=21) to mean +49pp (n=40, 3 seeds) (Figure 3). At , epochs 1–4 give similar lift (seed 42: +75/+79/+77 problems for ), suggesting the recipe is not highly sensitive to training duration once enough at-edge pairs are present. We did not run at this seed, so the plateau onset is an open question.
Math: auto-difficulty curriculum
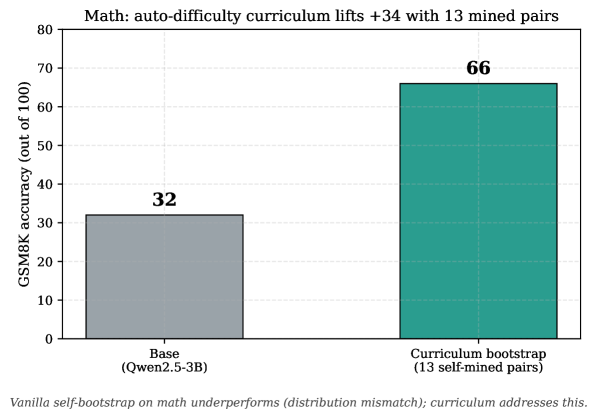
Applied to GSM8K on Qwen2.5-3B-Base, vanilla self-bootstrap is known to underperform on math (a distribution mismatch between self-generated arithmetic and GSM8K’s multi-step word problems; we observed regression in preliminary vanilla runs). The auto-difficulty curriculum (Section 2.3) resolves this. With 13 self-mined pairs, the curriculum-trained model reaches 66/100 from a base of 32/100 on GSM8K — a doubling with no human-written training data (Figure 4).
Cross-architecture and cross-generation
Cross-generation. The recipe transfers from Qwen2.5 (2024) to Qwen3 (2025) when there is headroom. Qwen3-4B-Base lifts +16.5pp on HumanEval with the simple 40-pair recipe; Qwen3-8B-Base saturates (pp).
Cross-architecture. Pairs mined on Qwen2.5 do not transfer to Llama-3.2-3B (HE , MBPP when trained on Qwen-mined pairs). With own-mined pairs (32 mined from MBPP-train problems on Llama), the recipe lifts Llama-3.2-3B HumanEval by +4pp (3943) and is flat on MBPP-test. The cross-architecture lift is positive but modest; pairs must be model-native.
MBPP coverage.
Beyond the headline HumanEval numbers, MBPP-sanitized was measured for Qwen3-4B-Base (135148, +13 problems / +6.5pp), Qwen2.5-Coder-7B-Base (122124, +2), Llama-3.2-3B (9595, flat), and OLMo-2-7B-Base (45, noise). MBPP magnitudes mirror HumanEval qualitatively: positive on under-trained bases, flat/zero on bases with limited code skill or saturated bases.
Cross-family cautions. On OLMo-2-7B-Base (HumanEval base 3%), the recipe regresses (pp). The model is too weak on code to produce well-formed mined material.
Failure modes and methodology lessons
We report seven negative or marginal-result paths cleanly. These are valuable: each pins down a specific failure mode of self-bootstrap and may save future researchers time.
(a) Self-correction over-correction.
Inspired by o1-style reasoning, we tried mining wrong “wait, let me reconsider” correct triples on MATH problems. Training Qwen3-4B-Base on 67 such triples produced a catastrophic regression: 299/500 69/500 (). Diagnosis: training only on wrongfix teaches the model to second-guess itself even when its first attempt was correct.
Fix: mix 67 wrongfix triples with 100 rightstays-right examples (greedy was correct, no “wait”). Re-training produces a small positive lift: 303/500 308/500 (). The methodology lesson is general: any self-correction training must include positive examples where the model commits, not just examples where it corrects.
(b) Recursive self-bootstrap plateau.
We tested whether iterating the recipe (iter 1 mines pairs from base adapter ; iter 2 uses to mine pairs on new problems adapter ; iter 3 similarly) compounds capability. On Qwen2.5-3B with 200 MBPP-train problems per iter:
-
•
iter 1: HE pre-train 16, post-train 12 (regression)
-
•
iter 2: HE pre-train 13, post-train 13 (flat)
-
•
iter 3: HE pre-train 15, post-train 15 (flat)
No compounding. Cumulative pairs grew (36 74 74) but lift plateaued.
(c) Tree-shaped training data degrades plain-prompt evaluation.
We attempted four variants of “mine multiple solution approaches per problem; train on the full multi-approach trace.” All four regressed on plain-prompt HumanEval (, , , ). Training on traces that include failed candidate code teaches the model to occasionally emit failing code; even filtering to keep only the winning approach injects a multi-step preamble that conflicts with plain-prompt evaluation format.
(d) Distribution mismatch.
Mining HE-style pairs and evaluating on BCB-Hard (library-fluency) yields flat results (Qwen3-8B: on BCB; Qwen3-4B: on BCB). Mining self-generated easy math and evaluating on MATH-500 yields catastrophic regression ( on Qwen3-8B; on Qwen3-4B). Mining must match the eval distribution closely.
(e) ARC-AGI: silent infrastructure crash.
We attempted self-bootstrap on ARC-AGI-1 with Qwen3-8B-Base and the “model writes Python transform function, verifier runs against task train examples” approach. The vLLM engine crashed silently during model load on our pod; we did not recover before our compute budget expired.
(f) Cross-domain transfer is marginal.
We trained a recipe on code-only pairs (48 mined from MBPP-train) with Qwen2.5-3B-Base and evaluated on math without any math training data: HumanEval moved 13/8012/80 (flat), MATH-500 moved 37/10039/100 (). The math lift is within noise. We interpret this as weak evidence that code-trained recipes transfer cross-domain to math; a stronger cross-domain claim would require larger pair counts and multi-seed validation.
(g) Diversity-cued mining yields too few pairs to help.
We prompted the model with explicit cognitive “lenses” (brute force, math formula, hash structure, recursion) during pair generation, hoping to broaden the at-edge pool. Yield was low (8 pairs from 150 problems) and the resulting LoRA was within noise of base (HE from 16/16418/164). The cued-prompt strategy may need a stronger base model and many more attempts per problem to reach a useful pair count.
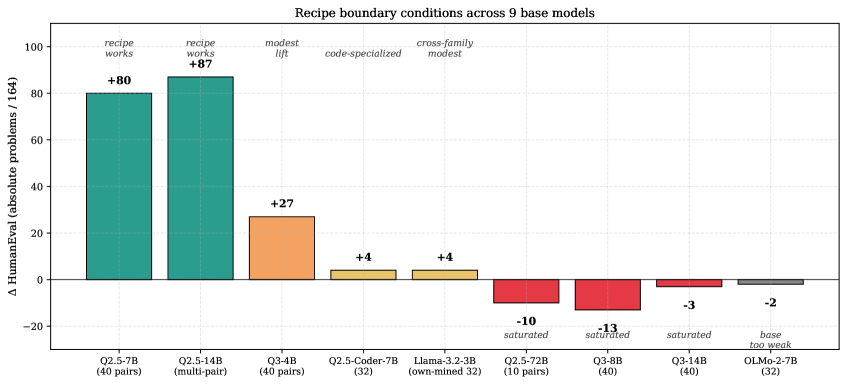
Boundary conditions summary
Across 9 base models we observe four conditions under which the recipe fails (Table 4).
| Failure mode | Example | Diagnosis |
|---|---|---|
| Saturation | Qwen2.5-72B ; Qwen3-8B ; Qwen3-14B | Base too strong; few mining candidates fail |
| Distribution mismatch | BCB-Hard ; MATH-easy | Train and eval distributions differ |
| Base too weak | OLMo-2-7B 3% base | Mined pairs are noise; model can’t generate well-formed problems |
| Cross-family pair non-transfer | Llama-3.2 trained on Qwen-mined: HE | Tokenizer/pretraining mismatch; need own-mined pairs |
Related work
Self-improvement with verifiers.
STaR [1] and Rejection-Sampling Fine-Tuning (RFT) [2] generate model rationales conditioned on external problem sets and fine-tune on the correct subset. We differ in (i) using model-generated problems with no external set, (ii) mining paired (broken, fixed) examples rather than retaining only correct rationales, and (iii) introducing the auto-difficulty curriculum. R1-Zero [3] uses GRPO with verifiable rewards; we use SFT with mined pairs on a much smaller scale. Self-Refine [5] and Reflexion [6] use self-correction at inference time without training updates; our Section 3.10(a) explores the training-time analog and documents its failure mode.
Test-time scaling.
Codex pass@ [9] introduced the metric in 2021. AlphaCode [15] used massive sampling and verifier-based filtering for competitive programming. Self-Consistency [16] pioneered majority-vote selection without external verifiers. Snell et al. [17] formalize test-time compute as a scaling axis. The o1-class models (e.g., OpenAI o1, DeepSeek-R1) extend this with sophisticated tree search and verifier learning. Our contribution is empirical quantification on small modern open bases, where prior tabulated numbers are scarce.
Synergy between training and inference scaling.
Snell et al. [17] study the trade-off between training compute and test-time compute. Our recipe TTS interaction (Section 3.5) is, to our knowledge, the first concrete documentation of a threshold regime where below-threshold recipe training degrades TTS performance — not a smooth trade-off but a sign change.
Discussion
What the recipe actually does.
The control experiment isolates the contribution: the model’s own at-edge failure patterns carry the training signal. Mechanically-corrupted external pairs do not. The recipe operates by extracting and re-exposing the model’s latent competence rather than introducing new knowledge.
Recipe vs. TTS, regime-dependent.
Our central finding is that the relative value of recipe-style fine-tuning and test-time sampling depends on regime:
-
•
Under-trained recipe: 36 pairs on 3B; recipe degrades TTS by 4.9pp.
-
•
Well-trained recipe: 132 pairs on 14B; recipe + TTS exceeds either alone by 12.8pp.
This implies a sample-budget consideration: small mined-pair counts on small bases should defer to TTS-only; deployment scenarios that justify the training cost (and provide enough pairs) gain from the combination. The transition point and its model-size dependence are open questions.
Modern bases vs. older bases.
The recipe alone gives its largest absolute lifts on under-trained 2024-era bases (Qwen2.5-7B/14B) and modest lifts on modern 2025 bases (Qwen3-4B). On saturated modern bases (Qwen3-8B+, Qwen2.5-72B), recipe regresses. The recipe’s primary use case is therefore lifting models with code-skill headroom on the target benchmark — not lifting models that already approach the benchmark ceiling.
Negative findings as evidence.
Five negative paths (Section 3.10) document failure modes that may save future practitioners time: self-correction over-correction (and its fix), recursive plateau, tree-shaped training data side effects, distribution mismatch with concrete examples, and base-capability requirements. The over-correction mixed-trace recovery is a methodology contribution in its own right.
Limitations
-
•
Single-seed for 14B: our headline 80.5% multi-pair result is single-seed; we have 3-seed validation only at 7B and 21-pair scale.
-
•
LiveCodeBench: we did not evaluate on the most recent contamination-resistant code benchmark; HumanEval+ is our best contamination-resistance evidence.
-
•
Math beyond GSM8K: the auto-curriculum is validated on GSM8K only; on MATH-500 we observe negative findings (distribution mismatch) without a positive recipe.
-
•
Self-consistency at one model size: we report SC on Qwen3-1.7B; broader replication is desirable.
-
•
Synergy threshold mapping: we report two data points (3B/36 pairs negative; 14B/132 pairs positive); the threshold’s exact shape (varying pair count, varying model size) is not characterized.
-
•
ARC-AGI incomplete: we attempted but did not complete an ARC-AGI evaluation.
-
•
Cross-family transfer is partial: Qwen-mined pairs do not transfer to Llama; own-mined pairs give a small lift; cross-family generalization is not established at scale.
-
•
Verifier requirement: oracle pass@ requires test cases; deployable settings need self-consistency or a learned verifier, both of which lose some of the oracle’s benefit.
Conclusion
We presented TinyForge-Zero, a study of self-bootstrap and test-time sampling for lifting open base models on code and math benchmarks. The recipe alone takes Qwen2.5-14B-Base from 26.8% to 80% on HumanEval pass@1 (74.4% on HumanEval+); test-time sampling alone takes Qwen3-4B-Base from 48.2% to 92.7% with no training. Their combination is regime-dependent: recipe adds to sampling at sufficient training scale, but hurts sampling at small scale — the first documentation of this synergy threshold. Seven negative or marginal paths are documented alongside the positive ones, including the catastrophic-then-fixed self-correction over-correction — a recipe lesson with general implications.
All experiments use single-GPU consumer-rentable instances at under $50 total compute. All code, mined pairs, and a reproduction guide are released at https://github.com/ranausmanai/tinyforge-zero; the LoRA adapter weights for the 14B run are mirrored on Hugging Face Hub.
References
- [1] Eric Zelikman, Yuhuai Wu, Jesse Mu, Noah D. Goodman. STaR: Bootstrapping Reasoning With Reasoning. NeurIPS, 2022.
- [2] Tianbao Yuan et al. Scaling Relationship on Learning Mathematical Reasoning with Large Language Models. arXiv:2308.01825, 2023.
- [3] DeepSeek-AI. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948, 2025.
- [4] Qwen Team. Qwen2.5-Coder Technical Report. arXiv:2409.12186, 2024.
- [5] Aman Madaan et al. Self-Refine: Iterative Refinement with Self-Feedback. NeurIPS, 2023.
- [6] Noah Shinn et al. Reflexion: Language Agents with Verbal Reinforcement Learning. NeurIPS, 2023.
- [7] Weizhe Yuan et al. Self-Rewarding Language Models. arXiv:2401.10020, 2024.
- [8] Mark Chen et al. Evaluating Large Language Models Trained on Code (Codex). arXiv:2107.03374, 2021.
- [9] Mark Chen et al. Evaluating Large Language Models Trained on Code (Codex). arXiv:2107.03374, 2021.
- [10] Jiawei Liu et al. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation. NeurIPS, 2023.
- [11] Jacob Austin et al. Program Synthesis with Large Language Models. arXiv:2108.07732, 2021.
- [12] Karl Cobbe et al. Training Verifiers to Solve Math Word Problems. arXiv:2110.14168, 2021.
- [13] Dan Hendrycks et al. Measuring Mathematical Problem Solving With the MATH Dataset. NeurIPS, 2021.
- [14] Naman Jain et al. LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code. arXiv:2403.07974, 2024.
- [15] Yujia Li et al. Competition-Level Code Generation with AlphaCode. Science, 2022.
- [16] Xuezhi Wang et al. Self-Consistency Improves Chain of Thought Reasoning in Language Models. ICLR, 2023.
- [17] Charlie Snell et al. Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters. arXiv:2408.03314, 2024.